Starting the early 2000s, the improvements in hardware to support deep learning networks has lead to a leap in modern deep learning approaches. Deep Learning (Hinton et al. 2006), (Bengio et al. 2007), which is an extension of neural networks, contain an input, an output, and a large number of hidden layers between the input and output. This type of an architecture is able to capture non-linear relationships in data, and are better at modeling data. Deep learning works much better than their Machine Learning predecessors as shown by their performance in several types of benchmark datasets such as SQuAD (The Stanford Question Answering Dataset, GLUE (General Language Understanding Evaluation), XTREME ((X) Cross-Lingual Transfer Evaluation of Multilingual Encoders) and others. Deep learning is applicable to a large variety of applications ranging from Natural Language Processing, Speech Recognition, Computer Vision etc. For this doc, I will focus on Deep Learning as it pertains to Natural Language Processing, as it gives me the opportunity to delve deeper into LLMs - the newest kid on the block with Deep Learning. This doc is split into the following layout:
I describe the foundational improvements that have been made in every aspect of the deep learning architecture to bring us to where we are today. Although compute and data are 2 major areas which have enabled Deep Learning as it is today, my focus for this doc is on architecture and algorithmic improvements.
From ML to Deep Learning
A simplified type of a neural network with a single hidden layer, require the following to train a model:
- Feature representation
- Loss function (such as cross entropy loss)
- Classification function (such as sigmoid)
- Optimizers (such as gradient descent) Grounding our understanding of ML in terms of these, we can observe significant improvements in each of these areas, which has enabled deep learning to be as prevalent and effective as it is today. Deep Learning has enabled generalization of knowledge, and the possibility of pre-training on generic data and fine tuning to a specific domain (domain adaptation), without the need for any hand coded feature generation. This has lead to the new area of Transfer Learning.
In the rest of this section I will describe some foundational improvements that Deep Learning has provided based for every aspect of a neural network on the following high level areas, which makes deep learning work so well in practice compared to previous approaches.
Feature Representation
In Machine Learning (ML), a rich feature representation is required as input for an ML model to learn from the data. Previously this was done using feature engineering, and hand-coding of features. However, with deep learning, the input is now either pretrained embeddings or the features/embeddings that are learned from running text by the deep learning neural network. More details about the evolution of feature representation and vector semantics is provided in Appendix A.
In 2003 Bengio at. al. introduced a revolutionary new intuition of using running text as supervised training data to predict whether a word “a” is more or less likely to show up near another word “b”. This avoids the need for any hand-labeled data for supervised classification. The authors applied this approach for language modeling and illustrate how this approach improves perplexity (branching factor) of the model over existing n-gram approaches.
In 2013, Word2Vec (Mikolov et al. 2013) was introduced, which used running text as input to a binary classification model to to classify whether a word exists in the neighborhood of another word. Word2vec used 2 approaches to accomplish this: Skip Gram with Negative Sampling (SGNS), Cumulative bag of words (CBOW). With SGNS, for each target word, we treat the neighboring context words (within a window of words) as positive samples, and then randomly sample words from the rest of the lexicon and use them as negative samples. This is then provided as input to the classifier, which distinguishes between the positive and negative samples. The weights that are learned from the classifier are treated as the embeddings. Word2Vec has some shortcomings, as it can only provide static embeddings, and not different embeddings based on contextual information. This means that the words “bank” would be the same embedding irrespective of whether it is mentioned in the context of a “river bank” or a “financial institution bank”. Word2Vec also had trouble dealing with unknown words, as it tokenized based on words/phrases. Finally, Word2Vec could not handle word dependencies longer than the window of the surrounding text. In 2014 GloVe (Pennington et. al 2014) built on top of the limitations of Word2Vec, and not only used local context (like word2vec) but also global context to capture the the relationship between two words or phrases. GloVe is better than word2vec at handling rare words, because of global relationships between rare words and common words is captured by the model. Like Word2Vec, GloVe also worked on word or phrases as the smallest tokens, and had trouble working with unseen words. In 2017 Fasttext (Bojanowski et al., 2017) was introduced which works with subword instead of words or phrases. This means that it would handle rare words much better, as it tokenized the words into their subwords. E.g. “let’s” would be broken down into “let” and “‘s” and their embeddings would be learned independently. In 2018 (Peters et.al. 2018) proposed ELMo that is able to capture the concept of contextual embeddings (which addresses the “bank” problem above. ELMo as built on bi-directional RNN layers, capturing the embeddings of it from the forward and backward pass of the RNN. More recently there are newer representations of embeddings using the transformer architecture (such as BERT, TransformerXL, ChatGPT and others).
Tokenization and Subwords
Creating embeddings at subword level is able to help us deal with unknown words much better than before. Now, we cam compose the definition of a new word based on it’s subcomponents. In 2015, (Sennrich et al. 2015) explored working with Byte-Pair Encoding (BPE) (Gage, 1994) that is originally a compression algorithm to encode running text. This helps capture text better than existing tokenization approaches, but as it works with unicode characters (144,697 unicode characters!), the unicode combinations are sparse. In 2016, Google introduced WordPiece (Wu et. al. 2016) which was the internal tokenizer used by BERT. In 2018 (Kudo and Richardson, 2018) introduced SentencePiece as a much more performant, and principled approach for subword encoding as compared to BPE alone. SentencePiece combines BPE with the Unigram model. SentencePiece was used to train T5 Language Model. In (Bostrom and Durett, 2020)) the authors mention that BPE is not an effective way to train LLMs.
Non-Linear Activation functions
Activation functions are used in the hidden layers of deep learning architecture, which each individual node takes in input from the previous layer, and performs an operation on them. The goal of activation functions is to be able to capture complex data from the input, without loss of information. Existing activation functions, such as Sigmoid cannot represent more complex data representations, and is heavily prone to gradient saturation for values close to 0 or 1. Explaining this a bit more, we know that:
Sigmoid Activation is $(y = 1 / (1+e^{(-z)}))$, where $z = sum (w_i * x_i) + b$
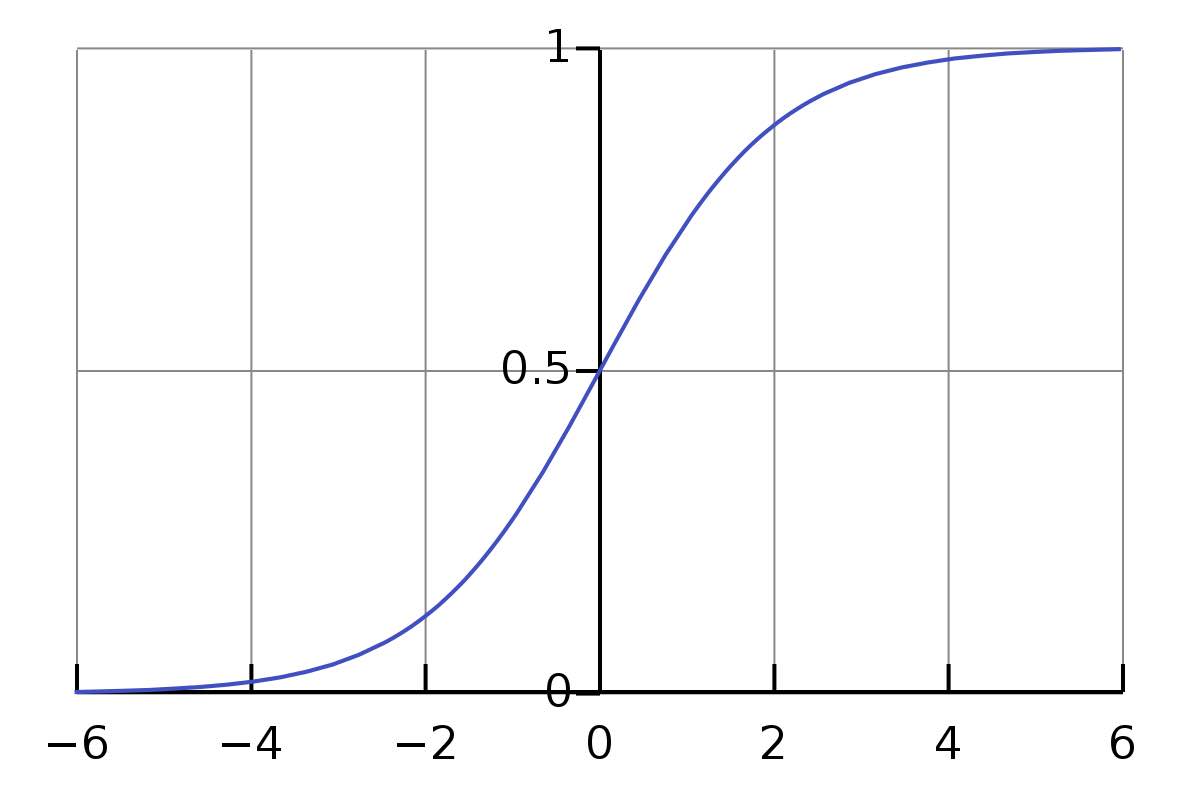
Fig 1: Sigmoid Activation Function: Image Credit - Wikipedia
This z value is converted into a probability by using an activation function such as sigmoid. The problem with sigmoid is that it squashes outliers towards 0 or 1, making it challenging to capture outlier data, as it causes problems getting derivatives and propagating it back to the first layer using Backprop. This problem is also known as the Vanishing Gradients Problem. To address this, deep learning has explored with non-linear activation functions such as Rectified Linear Units or ReLU (Nair and Hinton, 2010). ReLU has linear behavior for positive values, and zero activation for negative values. Using ReLU transforms the input space (such as XOR) into a linear space in the hidden layers, which can then be classified using a linear approach (Goodfellow 2016, page 169)
Relu Activation Function is: $y = ReLU(z) = max(z,0)$, where $z = sum (w_i * x_i) + b$
Newer activations functions are now used for LLMs. An image with ReLU, GeLU and others along with more details are covered in the next section regarding LLMs.
Optimizers and Backpropagation
Gradient Descent (GD) (Robbins and Monro 1951) is the algorithm to find the global minima in a gradient for all ML and Deep Learning algorithms.
In 2010, Stoachastic Gradient Descent (SGD) (Bottou, L. 2010), was introduced, which is what is used in practice (however more recent new approaches have evolved that are effective for training LLMs). GD requires all of the data to be processed once, after which it will update it’s parameters. This works for small amounts of data, but it prohibitive when working with large amounts of data for deep learning. In comparison to SD, SDG only requires a single datapoint (or a batch of datapoints - called mini-batch) to be processed before updating the parameters. SGD typically converges faster and is more memory efficient. SDG and GD both work with a constant learning rate (or step size), irrespective of whether it has encounted the same datapoint more frequently or less frequently. As a result, the learning is often more time consuming, or is stuck at a local minima. To address this Adagrad (Adaptive Gradient Descent) (Duchi 2011) performs gradient descent with varying learning rates for different parameters, increasing the learning rate for rare datapoints to push for faster convergence. Adagrad is able to handle sparse data much better than GD or SGD. Adam optimizer (Kingma and Ba, 2015), builds on Adagrad, and combines adaptive learning rates with moment. Adam maintains different learning rates for different parameters, and combines them with the first moment (mean of the gradients, providing the overall direction of the gradient) and the second moment (variance of the gradient, providing the magnitude of the gradient). This helps with faster convergence and adaptation to varied types of gradients. Other honorary mentions for optimizers are RMSProp, AdaDelta, AdaMax etc. which have their own nuances which need to be evaluated before leveraging for a deep learning problem. Improving the optimizers have enabled much faster convergence of Deep Learning Networks, handling sparse data better, and improved exploration of the landscape to avoid local minima.
Neural networks can contain a large number of stacked layers, where the output of the final layer needs to be propagated back to the first layer for learning. This is done using the error backpropagation or backprop (Rumelhart et al., 1986), (LeCun et. al. 1998).
Deep Learning Architectures, Regularization and Attention
Feed Forward Neural Networks
In 2003, (Bengio et al. 2003) first introduced the simple feed-forward language model primarily for language modeling. While previously, we were using n-gram language models, where ‘n’ usually ranged up to 3, neural language models, neural models are able to generalize over a larger context, and generalize better. The first feedforward neural network contained a single hidden layer, and was able to capture long distance dependencies much betters as compared to the n-gram approach and used running text as input to illustrate self-supervision.
Recurrent Neural Networks (RNN)
Recurrent Neural Networks are neural networks that have a cycle within the network, where the hidden layer computed in the previous iteration is leveraged as a form of context or memory for the next iteration.. This is very pertinent to language, which is largely dependent on the previous text/utterance. The first RNN language models were by (Mikolov et al., 2010). RNNs are used for Language Modeling (for machine translation), sequence/text classification and several other downstream tasks.
RNNs have been used for Machine Translation using en Encoder-Decoder architecture (also knows as seq-2-seq models). Here an encoder takes in an input sentence and converts it into an embedding of some form, which is taken as input by the decoder and converted into text in another language. Encoder Decoder architectures have been widely successful and also have been applied to tasks such as question answering, textual entailment, summarization etc. The intuition behind this is that the output text is a function of the input text (e.g. answer is related to the question being asked), even though the output and input both belong to the same language.
Although RNNs capture the temporal nature of language and dependence on previous words, it has a limitation of not being able to parallelize the processing, as each token can only be processed after the previous token is processed and the weights from the hidden layers are passed to it. Another limitation of this was the problem of vanishing gradients, meaning that the gradients brought from the hidden layer were subjected to so many multiplications, that they eventually ended up becoming 0. This lead to the problem of long distance dependencies not accurately captured.
Long Short Term Memory Networks (LSTM)
LSTMs (Hochreiter and Schmidhuber, 1997) started being used to mitigate the issues introduced by RNNs, in particular regarding RNNs not being able to address or make use of long distant information. LSTMs introduced gates that selectively passed information from the input layer and also the hidden layer from the previous node.
Regularization to avoid Overfitting
In order to avoid overfitting, various forms of regularization are used. One of the most important ones is called - dropout. Dropout is when we randomly drop some units and their connections from the network during training (Hinton et al. 2012), (Srivastava et al. 2014). Hyperparameter tuning is another important requirement to avoid overfitting or being stuck at a local minima.
Attention Mechanisms
In 2014 (Bahdanau 2014) introduced the concept of Attention in Deep Neural Networks, which addressed the botteneck issue that was introduced by RNNs (where the data at $n-1$ needed to be processed before data at $n$ so that data $n$ could use the hidden layer as input from data $n-1$). Using the attention mechanism, data n could get hidden states from all of the previous data points, and not just data $n-1$. This was explained from the context of a machine translation task where the encoder created hidden layers for all of the items in the input, and all these hidden layers were provided to the decoder in the form of a context vector, which is a function of all the hidden layers.
There are different types of attention mechanisms. Dot-product attention is one such approach, where all the hidden layers from the past few contexts are combined in the form of a dot product, and taken to the decoding layer of an RNN.
Transformers for Transfer Learning and Contextual Embeddings
Self Attention and Transformer Architecture
In 2017, (Vaswani et al., 2017), proposed the original transformer architecture which was based on two lines of prior research: self-attention (Bahdanau 2014) and memory networks (Sukhbaatar et al., 2015). Transformer is based on the concept of attention, and it replaces RNNs and the bottlenecks introduced by it. In the original Transformer paper, it consists of an encoder and a decoder. In the encoder, Transformers use fully connected feed forward neural networks where each input token is connected with all the past tokens in a step called Self-Attention. Using this, and extending it to multi-head attention where each token is performing self-attention in parallel, the encoder is able to capture the dependency relationships between each token in the input. Transformers also add positional encoding (one hot encoding) of the position of the token in the sequence to capture word order, thereby replacing the need for RNN like architecture to encode the sequential dependency of a word/token on previous tokens. The encoder and decoder both contain similar stacked layers of self attention and fully-connected networks. Transformers allow parallel computation (which RNN’s could not). Transformers also introduce Layer Normalization (scaling the dot products after each layer), which is able to address the vanishing gradients problem that RNNs, LSTMs and other approaches could not address. Today, Transformers are the cornerstone all language models for autoregressive generation (gen AI). There are several improvements that have been made to vanilla transformers to train LLMs as they are today.
![]()
Fig 2: Vanilla Transformer Architecture
Limitations of Transformers
Attention is quadratic in nature (because at token $n$, we are computing context for $n$ and all the previous $n-1$ tokens. As a result, Transformer architectures have not able to address very long documents. Some approaches that have been introduced to address this approaches like Longformer (Beltagy et. al 2020), where the attention mechanism scales linearly with sequence length. This enables processing much longer texts as compared to the vanilla transformer approach. More recently newer attention mechanisms have been introduced to address the quadratic nature of attention. Details are in the Pre-Training section of LLMs.
Transformer Based Models
In 2019, BERT (Devlin et. al. 2019) was introduced which has two objective functions: Masked LM, and NSP (Next Sentence Prediction), so that it would learn bidirectional information from within a sentence, and learn about dependencies between 2 sentences. It was one of the first initiatives that showed contextual embeddings. Also, honorable mention to ELMo (Peters et. al 2018) which was the first initiative for contextual embeddings, but it did not use the transformer architecture. Other transformer inspired early approaches are: RoBERTa (Liu et al. 2019), Distilbert (Sanh et. al. 2019), TransformerXL (Dai et. al. 2019), T5 (Raffel 2019). Deep Learning is able to generalize for unseen data much better than their Machine Learning counterparts. (Erhan et al. 2010) discuss the important of pretraining for deep learning tasks.
From Deep Learning and transformers to Large Language Models
More recently researchers have observed that model scaling can lead to an improved model capacity (ability to represent complex patterns that is it trained on) and significant improvement in performance in downstream tasks. It is also discovered that this new era of Large Language Models (that have 10B parameters or more) exhibit some emergent capabilities (such as in context learning), that have not been present in small scale language models (such as BERT, DistilBERT etc. - which have Millions of Parameters only).
In 2018, GPT-1 (Radford et. al. 2018) which stands for Generative Pre-Training was developed using a generative decoder only Transformer Architecture. GPT-1 adopted an approach of pre-training followed by supervised fine-tuning. GPT-1 is a 117MM parameter model.
Later in 2019, GPT-2 (Radford et. al. 2019), followed a similar approach as GPT-1, but increased the number of paramerters to 1.5B. It aimed to perform tasks without explicit fine tuning using labeled data. To enable this, the authors introduced a probabilistic approach for multi-task solving p(output|input, task), where the output is conditioned not only on the input, but also the task.
GPT-3 (Brown et. al. 2020) was released in 2020, and it scaled the number of model parameters to 175B. The authors introduce the concept of in-context learning, which uses LLMs in a few-shot or zero shot way. This means that the pre-training and prompting (with in-context information) will help the model converge to an answer within the context of the information provided.
GPT-4 (OpenAI, 2023) was released in 2023 (March) and it extended text input to multimodal signals. GPT-4 shows strong capabilities in solving complex problems as compared to previous models. A recent study by (Bubeck et. al 2023) showed that GPT-4 can perform better at a variety of tasks of different domains (such as mathematics, coding, vision, medicine, law, psychology and more), and performs very similar to human results. The paper shares that this is the beginning of AGI (Artificial General Intelligence)
Huggingface recently released the Bloom model (HuggingFace 2022) which has multilingual support for 46 natural languages and 13 programming languages, and Meta has released LLaMA (Touvron et. al. 2023) has 65B parameters . All of these are generative language models and they have moved us several leaps into NLP tasks such as : question answering, multi-task learning (Radford et. al. 2019), and others, and also have shown emergent abilities that can be observed using prompting. These generative models are also evaluated using prompting, which has lead to a whole new way of debugging language models, and learning about what these LMs know and how they can be leveraged in other areas.
(Chen et al, 2023) provide a detailed survey of LLMs and what it has taken for us to get this far with them.
Why Do LLMs work?
Scaling Laws
KM scaling law (Kaplan et. al. 2020) by open AI proposed a power law relationship of model performance with respect to three major factors - Model Size, Datset Size and amount of training compute.
The Google DeepMind team (Hoffmann et. al. 2022) proposed another study (Chinchilla Scaling Law) which is an alternative form of scaling for training LLMs.
Below is an image of how the number of parameter of a model have expanded over the years.
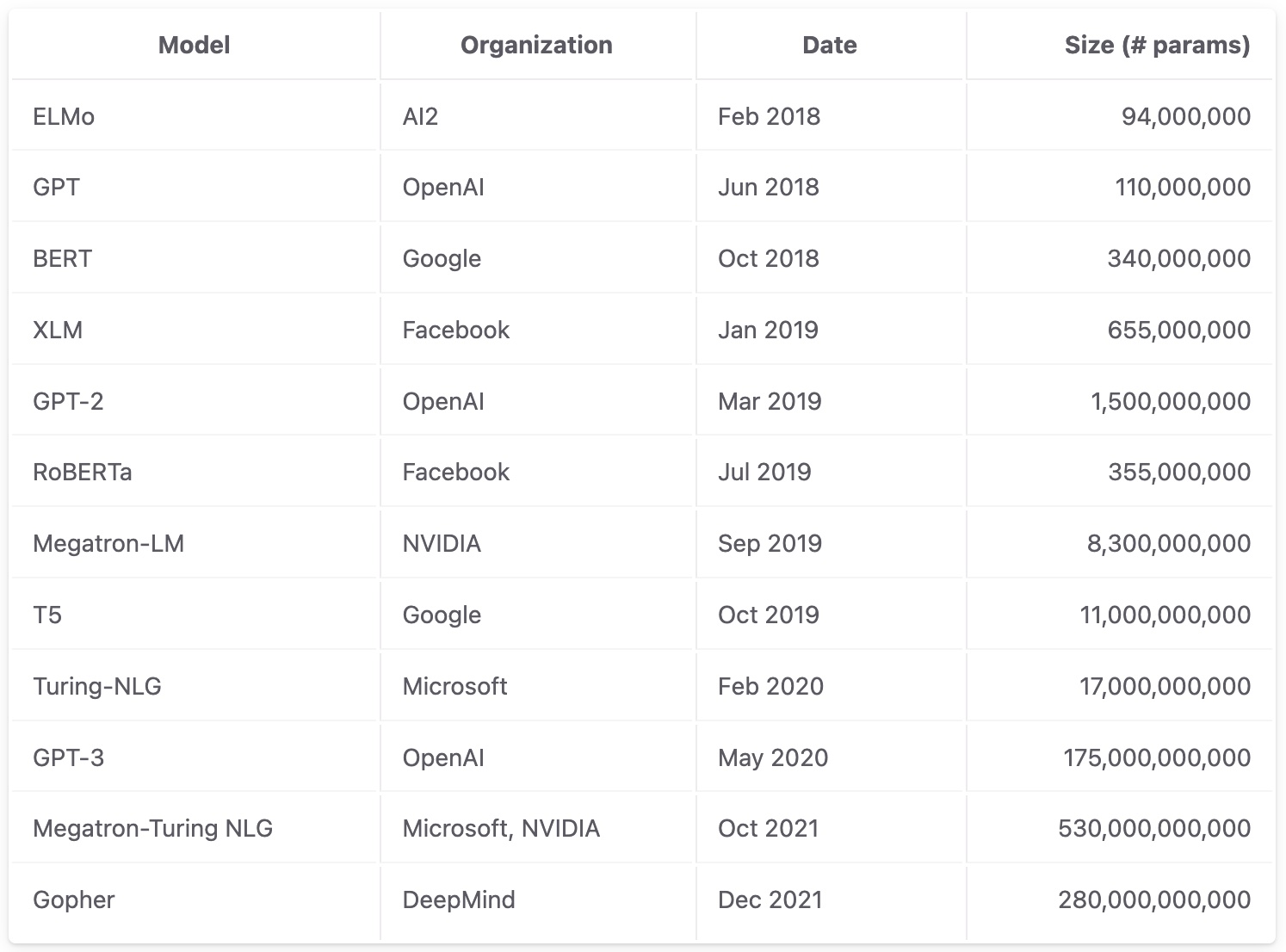
Fig 4: Image Credit: Stanford LLM Course
Emergent Abilities of LLMs
LLMs introduced a new set of abilities that were not previously present in the smaller models (such as BERT), but were introduced when models were scaled to a much larger size. Some of these abilities include:
- In-context learning: This learning ability was formally introduced by GPT-3 (Brown et. al. 2020) where given that a model is provided with some task demonstrations, it can generate the output text by completing the word sequence of the input text.
- Instruction Following: After fine tuning on instruction datasets, LLMs are able to follow and execute tasks for new datasets.
- Step-by-Step Reasoning: Using chain-of-thought (CoT)(Chung et. al. 2022) prompting approaches, LLMs are able to solve step by step reasoning steps.
Pre-training of LLMs
LLMs rely on a massively large corpus of data for training. Most LLMs such as GPT-2 (Radford et. al. 2019) and PaLM (Chowdhery et. al 2022) are trained on generic datasets that are a collection of books, webpages and conversational text, as this generic data and introduce general purpose capabilities to the language model. CommonCrawl is one of the biggest sources of web data, and Reddit corpora is one of the biggest sources of conversational text. Several LLMs such as PaLM (Chowdhery et. al 2022) and Bloom (Huggingface 2022) also use specialized text data for training. This includes data like multilingual text, scientific text (research papers) and code (from stack exchange or Github). In order to train with this data, several preprocessing steps are performed to remove redundant, private data, irrelevant data or toxic data from the text. The text is encoded into subword tokenizers (some of which was discussed in the Subwords Section).
Once the data requirements are established (all LLMs need to have large amounts of data and high quality data for optimal performance), the data is passed through one of the many architectures such as encoder-decoder architecture (used by BART, T5, causal decoder architecture (for next word prediction and used by GPTs, BLOOM), or the more recent Prefix Decoder (used by PaLM) Architecture. There has been a lot of research around the best location of layer normalization, and pre, post or sandwich layer norms are some different approaches used with the architecture.
Activation functions used by LLMs are different from Deep Learning activations that I discussed in the previous section. These are largely GeLU (Gaussian Error Linear Unit) (Hendrycks 2016) or variants of GLU activation (Shazeer 2020) such as SwiGLU (Shazeer 2020) and GeGLU (Shazeer 2020). Below is an image of GELU activation function as compared to RELU and ELU (Clevert et. al. 2016).
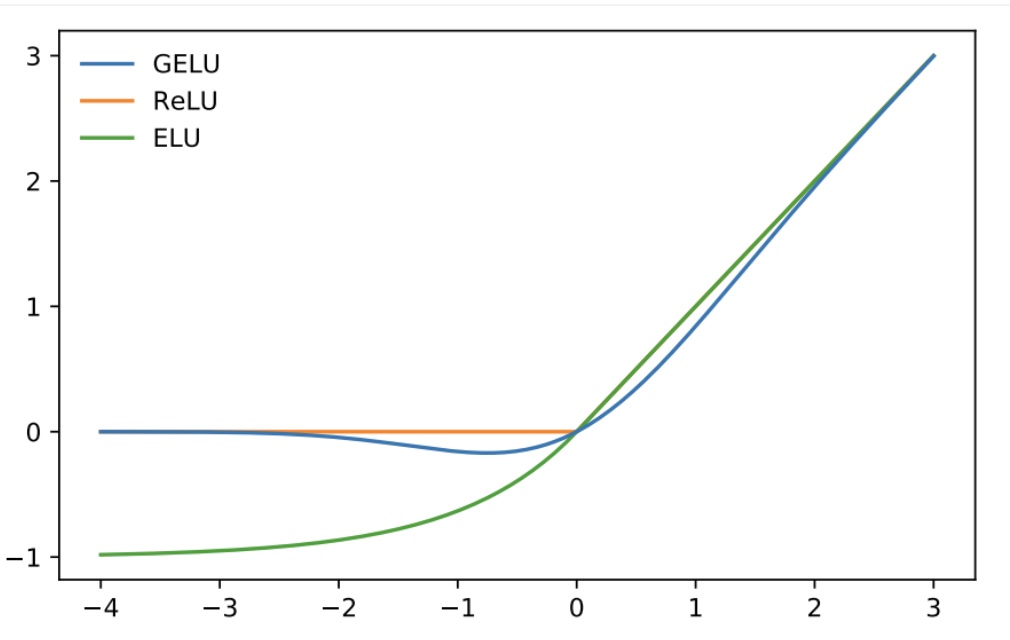
Fig 5: Image Credit: Papers with Code
Position embedding (as absolute positional encoding) as presented in the vanilla Transformer architecture has several new variations proposed, such as relative positional embedding, Rotary position embedding, and AliBi (Press et. al. 2022)
Several different types of attention mechanisms can be used for LLMs today. For instance, sparse attention approaches are used to address the quadratic computational complexity by the vanilla transformer. GPT-3 uses factoid attention (Child et. al. 2019) where instead of full attention, each query can only be attended to by a subset of tokens based on positions. Another type of Attention is multiquery attention (Shazeer 2019) where the same linear transformation matrices are shared by different heads. Another approach is FlashAttention (Dao et. al, 2022) which proposes optimizations based on memory consumption of memory modules on GPU.
There are 2 common objective functions used - language modeling (predict the next word given the previous word), or denoising autoencoding. During training, GPT-3 (Brown et. al. 2020) and PaLM (Chowdhery et. al 2022) have introduced a new strategy that dynamically increases the batch size during training. New LLMs also adopt a similar strategy with learning rates, where the learning rate is gradually increased to the maximum value, followed by a decay strategy. The optimizers used are ADAM (Kingma and Ba 2015), or variations of it such as ADAMw (Loshchilov and Hutter 2017).
Training - support for distributed training
The training for LLMs is optimized using three commonly used parallel training techniques - data parallism where the training corpus is distributed across GPUs, pipeline parallelism (Huang et. al, 2019) where multiple layers of the transformers are distributed across GPUs and tensor parallelism (where the tensor is decomposed and parallelized).
Adaptation Tuning for LLMs
Pretraining helps language models acquire general abilities for solving tasks. Most LLMs go through the next step of adaptation. There are 2 types of adaptation: instruction tuning (where abilities of LLMs are converted from language based to task based) and alignment tuning (where the output of the LMM is aligned with human preferences and values).
Instruction Tuning
In a recent paper, (Chen et. al, 2023) describe several datasets that are available for instruction tuning, and how instruction tuning has helped generalize to unseen tasks. In 2022, (Chung et. al. 2022) first experimented with Chain-of-Thought (CoT) prompting to show commonsense reasoning ability and mathematical reasoning ability.
Alignment Tuning
Regarding the second type of adaptation - alignment tuning - Open AI recently came out with their paper on InstructGPT (Ouyang et. al 2022) that helps further train models to align their output with human output. To align LLMs with human values (such as don’t use profanity, be polite, etc.) , Reinforcement Learning from Human Feedback (RLHF) (Christiano et. al. 2017) was proposed which leverages algorithms like Proximal Policy Evaluation (Schulman et. al. 2017) to adapt LLMs to human feedback. An RLHF system has 3 components - the LLM to be tuned, a reward model, an RL approach for training. In order to efficiently fine tune using RLHF, several efficient parameter tuning approaches are proposed such as Adapter Tuning (Houlsby 2019), Prompt Tuning (Lester et al., 2021), LoRA (Low-Rank Adaptation) etc. LoRA has been widely applied to open source LLMs (such as LLaMA and BLOOM)
Model Quantization
LLMs are challenging to deploy in the real world because of their prohibitive memory footprint. Model Quantization is the approach that is used for reducing the memory footprint of LLMs using popular model compression approaches. There are two quantization approaches - Quantization-aware training (QAT) (this requires a full model retraining) and post-training quantization (PTQ) (this requires no model retraining). Some PTQ approaches include Mixed Precision decomposition (Dettmers et. al. 2022), Per-Tensor Quantization (Xiao et. al. 2023), etc.
Final Thoughts
We have made tremendous progress in Deep Learning and NLP in the past few years, and although I have tried to cover a lot of the seminal work here, I wanted to emphasize that this is still a small drop in the massive amounts of work and research that has gone into this space. Some more concepts that are interesting and will be covered in future blog posts are - Knowledge Distillation, Quantization, Chain-of-Thought Prompting, in-context learning, Planning and Commonsense Reasoning using LLMs, Prompt Engineering, which hold promise for even bigger leaps into deep learning in the future.
References
[1] (Bahdanau et. al 2015) Bahdanau, D., K. H. Cho, and Y. Bengio. 2015. Neural machine translation by jointly learning to align and translate. ICLR 2015.
[2] (Beltagy et. al 2020) Iz Beltagy, Matthew E. Peters, Arman Cohan, Longformer: The Long-Document Transformer, 2004, arXiv
[3] (Bengio et. al 2003) Yoshua Bengio, Réjean Ducharme, Pascal Vincent, and Christian Jauvin. “A Neural Probabilistic Language Model.” Journal of Machine Learning Research, vol. 3, 2003, pp. 1137-1155.
[4] (Bengio et. al. 2007) Bengio, Y., P. Lamblin, D. Popovici, and H. Larochelle. 2007. Greedy layer-wise training of deep networks. NeurIPS.
[5] (Bottou 2010) Bottou, L. (2010). Large-scale machine learning with stochastic gradient descent. In Proceedings of COMPSTAT’2010 (pp. 177-186). Springer.
[6] (Brown et. al. 2020) Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, J. Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, T. Henighan, R. Child, A. Ramesh, Daniel M. Ziegler, Jeff Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, Dario Amodei. Language Models are Few-Shot Learners. NeurIPS 2020.
[7] (Bubeck et. al 2023) Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, Harsha Nori, Hamid Palangi, Marco Tulio Ribeiro, Yi Zhang, “Sparks of Artificial General Intelligence: Early experiments with GPT-4”, 2023
[8] (Chen et al, 2023) Zhipeng Chen and Jinhao Jiang and Ruiyang Ren and Yifan Li and Xinyu Tang and Zikang Liu and Peiyu Liu and Jian-Yun Nie and Ji-Rong Wen, “A Survey of Large Language Models”, 2023, arXiv
[9] (Child et. al. 2019) Rewon Child, Scott Gray, Alec Radford, Ilya Sutskever, Generating Long Sequences with Sparse Transformers, 2019, CoRR, abs/1904.10509
[10] (Chowdhery et. al 2022) Chowdhery, A., Narang, S., Devlin, J., Bosma, M., Mishra, G., Roberts, A., Barham, P., Chung, H.W., Sutton, C., Gehrmann, S., Schuh, P., Shi, K., Tsvyashchenko, S., Maynez, J., Rao, A., Barnes, P., Tay, Y., Shazeer, N.M., Prabhakaran, V., Reif, E., Du, N., Hutchinson, B.C., Pope, R., Bradbury, J., Austin, J., Isard, M., Gur-Ari, G., Yin, P., Duke, T., Levskaya, A., Ghemawat, S., Dev, S., Michalewski, H., García, X., Misra, V., Robinson, K., Fedus, L., Zhou, D., Ippolito, D., Luan, D., Lim, H., Zoph, B., Spiridonov, A., Sepassi, R., Dohan, D., Agrawal, S., Omernick, M., Dai, A.M., Pillai, T.S., Pellat, M., Lewkowycz, A., Moreira, E., Child, R., Polozov, O., Lee, K., Zhou, Z., Wang, X., Saeta, B., Díaz, M., Firat, O., Catasta, M., Wei, J., Meier-Hellstern, K.S., Eck, D., Dean, J., Petrov, S., & Fiedel, N. (2022). PaLM: Scaling Language Modeling with Pathways. ArXiv, abs/2204.02311.
[11] (Chung et. al. 2022) Hyung Won Chung and Le Hou and Shayne Longpre and Barret Zoph and Yi Tay and William Fedus and Yunxuan Li and Xuezhi Wang and Mostafa Dehghani and Siddhartha Brahma and Albert Webson and Shixiang Shane Gu and Zhuyun Dai and Mirac Suzgun and Xinyun Chen and Aakanksha Chowdhery and Alex Castro-Ros and Marie Pellat and Kevin Robinson and Dasha Valter and Sharan Narang and Gaurav Mishra and Adams Yu and Vincent Zhao and Yanping Huang and Andrew Dai and Hongkun Yu and Slav Petrov and Ed H. Chi and Jeff Dean and Jacob Devlin and Adam Roberts and Denny Zhou and Quoc V. Le and Jason Wei, Scaling Instruction-Finetuned Language Models, 2022, arXiv
[12] (Christiano et. al. 2017) Paul F. Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, Dario Amodei (2017). Deep reinforcement learning from human preferences. Advances in Neural Information Processing Systems 30 (NIPS 2017)
[13] (Clevert et. al. 2016) Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs), Djork-Arné Clevert, Thomas Unterthiner, Sepp Hochreiter, 2016
[14] (Dai et. al. 2019) Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, and Ruslan Salakhutdinov. “Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context.” Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019, pp. 2978-2988.
[15] (Dao et. al, 2022) Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, Christopher Ré, FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
[16] (Dettmers et. al. 2022) Tim Dettmers and Mike Lewis and Younes Belkada and Luke Zettlemoyer, LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale, 2022, 2208.07339, arXiv
[17] (Devlin et. al. 2019) Devlin, J., M.-W. Chang, K. Lee, and K. Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. NAACL HLT.
[18] (Duchi 2011) Duchi, J., Hazan, E., & Singer, Y. (2011). Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research, 12(7), 2121-2159.
[19] (Erhan et. al. 2010) D. Erhan, A. Courville, Y. Bengio, P. Vincent, “Why Does Unsupervised Pre-training Help Deep Learning?”, Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, PMLR 9:201-208, 2010.
[20] (Gage 1994) Philip Gage. 1994. A New Algorithm for Data Compression. C Users J., 12(2):23–38, February.
[21] (Goodfellow et. al. 2016) Goodfellow, I., Y. Bengio, and A. Courville. 2016.Deep Learning. MIT Press.
[22] (Hendrycks 2016) Dan Hendrycks, Kevin Gimpel, Gaussian Error Linear Units (GELUs), 2016, arxiv
[23] (Hinton et. al. 2006) Hinton, G. E., S. Osindero, and Y.-W. Teh. 2006. A fast learning algorithm for deep belief nets. Neural computation, 18(7):1527–1554.
[24] (Hinton et. al. 2012) G. E. Hinton , N. Srivastava, A. Krizhevsky, I. Sutskever and R. R. Salakhutdinov, Improving neural networks by preventing co-adaptation of feature detectors, CoRR, 2012
[25] (Hoffmann et. al. 2022) Jordan Hoffmann and Sebastian Borgeaud and Arthur Mensch and Elena Buchatskaya and Trevor Cai and Eliza Rutherford and Diego de Las Casas and Lisa Anne Hendricks and Johannes Welbl and Aidan Clark and Tom Hennigan and Eric Noland and Katie Millican and George van den Driessche and Bogdan Damoc and Aurelia Guy and Simon Osindero and Karen Simonyan and Erich Elsen and Jack W. Rae and Oriol Vinyals and Laurent Sifre, Training Compute-Optimal Large Language Models, 2022, 2203.15556, arXiv
[26] (Houlsby 2019) Neil Houlsby and Andrei Giurgiu and Stanislaw Jastrzebski and Bruna Morrone and Quentin de Laroussilhe and Andrea Gesmundo and Mona Attariyan and Sylvain Gelly, Parameter-Efficient Transfer Learning for NLP, 2019, CoRR, abs/1902.00751
[27] (Hochreiter and Schmidhuber, 1997) Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural computation, 9(8), 1735-1780.
[28] (Huang et. al, 2019) Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Mia Xu Chen, Dehao Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V. Le, Yonghui Wu, Zhifeng Chen, GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism, 2019, arXiv:1811.06965v5
[29] (Huggingface 2022) Huggingface, BLOOM: A 176B-Parameter Open-Access Multilingual Language Model, 2022 https://arxiv.org/abs/2211.05100
[30] (Kaplan et. al. 2020) Jared Kaplan and Sam McCandlish and Tom Henighan and Tom B. Brown and Benjamin Chess an Rewon Child an Scott Gray and Alec Radford an Jeffrey Wu an Dario Amodei, Scaling Laws for Neural Language Models, CoRR, abs/2001.08361, 2020
[31] (Kingma and Ba 2015) Kingma, D. and J. Ba. 2015. Adam: A method for stochastic optimization. ICLR 2015
[32] (Kudo and Richardson, 2018) Kudo, T., & Richardson, J. (2018). SentencePiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Brussels, Belgium.
[33] (LeCun et. al. 1998) LeCun, Y., Bottou, L., Orr, G., & Müller, K. (1998). Efficient backprop. In Neural Networks: Tricks of the Trade (pp. 9-48). Springer.
[34] (Lester et al., 2021) Lester, Brian and Al-Rfou, Rami and Constant, Noah, The Power of Scale for Parameter-Efficient Prompt Tuning, (https://aclanthology.org/2021.emnlp-main.243)
[35] (Levy and Goldberg 2014) Omer Levy, Yoav Goldberg, Neural word embedding as implicit matrix factorization, NIPS’14: Proceedings of the 27th International Conference on Neural Information Processing Systems - Volume 2 December 2014 Pages 2177–2185
[36] (Liu et. al. 2019) Liu, Y., M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov. 2019. RoBERTa: A robustly optimized BERT pretraining approach. ArXiv preprint arXiv:1907.11692.
[37] (Loshchilov and Hutter 2017) Fixing Weight Decay Regularization in Adam. I. Loshchilov, F. Hutter. 2017. Introduces AdamW.
[38] (Mikolov 2013) Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient Estimation of Word Representations in Vector Space. arXiv preprint arXiv:1301.3781.
[39] (Mikolov et. al. 2010) Mikolov, T., M. Karafiat, L. Burget, J. Cernock, and S. Khudanpur. 2010. Recurrent neural network based language model. INTERSPEECH.
[40] (Nair and Hinton 2010) V. Nair and G. E. Hinton, “Rectified linear units improve restricted boltzmann machines,” in ICML, 2010, pp. 807–814.
[41] (OpenAI, 2023) GPT-4 Technical Report, 2023, OpenAI
[42] (Ouyang et. al 2022) Long Ouyang and Jeff Wu and Xu Jiang and Diogo Almeida and Carroll L. Wainwright and Pamela Mishkin and Chong Zhang and Sandhini Agarwal and Katarina Slama and Alex Ray and John Schulman and Jacob Hilton and Fraser Kelton and Luke Miller and Maddie Simens and Amanda Askell and Peter Welinder and Paul Christiano and Jan Leike and Ryan Lowe, Training language models to follow instructions with human feedback, 2022, arXiv, 2203.02155
[43] (Pennington et. al, 2014) Pennington, J., Socher, R., & Manning, C. D. (2014). GloVe: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) (pp. 1532-1543).
[44] (Peters et. al. 2018) Peters, M. E., Neumann, M., Iyyer, M., Gardner, M., Clark, C., Lee, K., & Zettlemoyer, L. (2018). Deep contextualized word representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT) (pp. 2227-2237).
[45] (Press et. al. 2022) Press, Ofir and Smith, Noah A and Lewis, Mike, Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation, arXiv preprint arXiv:2108.12409, 2022
[46] (Radford et. al. 2018) Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving Language Understanding by Generative Pre-training.
[47] (Radford et. al. 2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. OpenAI Blog, 1(8), 2019.
[48] (Raffel et. al. 2019) Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., … & Liu, P. J. (2019). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. arXiv preprint arXiv:1910.10683.
[49] (Robbins and Monro 1951) Robbins, H., & Monro, S. (1951).A stochastic approximation method. The Annals of Mathematical Statistics, 22(3), 400-407.
[50] (Rumelhart 1985) D. Rumelhart, G. Hinton, and R. Williams, “Learning internal representations by error propagation,” UCSD, Tech. Rep., 1985.
[51] (Sanh et. al. 2019) Sanh, V., Debut, L., Chaumond, J., & Wolf, T. (2019). DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108.
[52] (Sennrich et. al 2016) Sennrich, R., Haddow, B., & Birch, A. (2016). Neural machine translation of rare words with subword units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (ACL), Berlin, Germany.
[53] (Shazeer 2019) Noam Shazeer, Fast Transformer Decoding: One Write-Head is All You Need, abs/1911.02150, 2019
[54] (Shazeer 2020) Noam Shazeer, GLU Variants Improve Transformer, 2020, CoRR, abs/2002.05202
[55] (Schulman et. al. 2017) John Schulman and Filip Wolski and Prafulla Dhariwal and Alec Radford and Oleg Klimov, Proximal Policy Optimization Algorithms, 2017, CoRR, abs/1707.06347
[56] (Srivastava et. al. 2014) Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, Ruslan Salakhutdinov; ‘Dropout: A Simple Way to Prevent Neural Networks from Overfitting’ JMLR 15(56):1929−1958, 2014.
[57] (Sukhbaatar et. al. 2015) Sainbayar Sukhbaatar, Arthur Szlam, Jason Weston, Rob Fergus, ‘End-To-End Memory Networks’, NeurIPS 2015
[58] (Touvron et. al. 2023) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample, LLaMA: Open and Efficient Foundation Language Models, 2023, arxiv
[59] (Vaswani 2017) A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in NIPS, 2017, pp. 6000–6010.
[60] (Pennington et al 2014) Pennington, J., R. Socher, and C. D. Manning. 2014. GloVe: Global vectors for word representation. EMNLP.
[61] (Wu et. al. 2016) Yonghui Wu, M. Schuster, Z. Chen, Quoc V. Le, Mohammad Norouzi, Wolfgang Macherey, M. Krikun, Yuan Cao, Qin Gao, Klaus Macherey, J. Klingner, Apurva Shah, Melvin Johnson, Xiaobing Liu, Lukasz Kaiser, Stephan Gouws, Y. Kato, Taku Kudo, H. Kazawa, K. Stevens, George Kurian, Nishant Patil, W. Wang, C. Young, Jason R. Smith, Jason Riesa, Alex Rudnick, Oriol Vinyals, G. Corrado, Macduff Hughes, J. Dean, Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. . 2016. Introduces WordPiece. Used by BERT.
[62] (Xiao et. al. 2023) Guangxuan Xiao and Ji Lin and Mickael Seznec and Hao Wu and Julien Demouth and Song Han, SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models, 2023, 2211.10438, arXiv
Appendix A: Word Vectors and Distribution Hypothesis
Embeddings and Vector Semantics
Distributional hypothesis first formulated in the 1950s by linguists like Joos (1950), Harris (1954), and Firth (1957), “Words that occur in similar contexts tend to have similar meanings”
Distribution Hypothesis was studied a lot in lexical semantics
- Word similarity: Two words that are similar to each other exist in similar contexts
- Word Relatedness: The meaning of two words can be related in ways other than relatedness similarity. One such class of connections is called word relatedness (Budanitsky association and Hirst, 2006)
- Topics and Semantic Field: One common kind of relatedness between words is if they belong to the same semantic field semantic field. A semantic field is a set of words which cover a particular semantic domain and bear structured relations with each other. For example, words might be related by being in the semantic field of hospitals (surgeon, scalpel, nurse, anesthetic, hospital), restaurants (waiter, menu, plate, food, chef), or houses (door, roof, topic models kitchen, family, bed). Semantic fields are also related to topic models, like Latent Dirichlet Allocation, LDA
Words as vectors
- Words as vectors: Osgood’s 1957 idea mentioned above to use a point in three-dimensional space to represent the connotation of a word, and the proposal by linguists like Joos (1950), Harris (1954), and Firth (1957) to define the meaning of a word by its distribution in language use, meaning its neighboring words or grammatical environments.
- Term document matrix: The term-document matrix was first defined as part of the vector space model of information retrieval (Salton, 1971).
- Term frequency: term frequency (Luhn, 1957):
- Inverse Document Frequency: (Sparck Jones, 1972)
- Pointwise Mutual Information: (Fano, 1961), (Church and Hanks 1989, Church and Hanks 1990)
Measurement of similarity:
- Cosine similarity - inner dot product between vectors
with sparse long vectors:
- Representing words as 300-dimensional dense vectors requires our classifiers to learn far fewer weights than if we represented words as 50,000-dimensional vectors,
- and the smaller parameter space possibly helps with generalization and avoiding overfitting.
- unable to handle unknown words
- independence assumption (which is untrue, and a very strong assumption to make)
- Dense vectors may also do a better job of capturing semantics, transfer learning, reasoning and other tasks that were previously hard to do.
Dense embeddings like word2vec actually have an elegant mathematical relationship with sparse embeddings like PPMI, in which word2vec can be seen as implicitly optimizing a shifted version of a PPMI matrix (Levy and Goldberg, 2014c).