In this post, we will break down NLP further and talk about Rule-Based and Statistical NLP. I will discuss why everyone needs to know about NLP and AI (Artificial Intelligence), how Machine Learning (ML) fits into the NLP space (it is indispensable actually) and how we are using it in our daily life even without knowing about it.
Introduction to NLP
Natural Language Processing or NLP is a phrase that is formed from 3 components - natural - as exists in nature, language - that we use to communicate with each other, processing - something that is done automatically. Putting these words together, we get Natural Language Processing or NLP - which stands for the approaches to “process” natural language or human language.
This is a very generic term. What does this “processing” even mean?
As a human, I understand English when someone talks to me, is that NLP? Yes! When done automatically, it is called Natural Language Understanding (NLU).
 |
| Human Understanding. Image Credit: http://www.stuartduncan.name |
I translated some Hindi to English for my friend, is that NLP? Yes, it is called Machine Translation (MT) when done automatically.
 |
| Machine Translation. Image Credit: Google Cloud |
As humans, we perform Natural Language Processing pretty well but we are not perfect; misunderstandings are pretty common among humans, and we often interpret the same language differently. So, language processing isn’t deterministic (which means that the same language doesn’t have the same interpretation, unlike math where 1 + 1 is deterministic and always equals 2) and something that might be funny to me, might not be funny to you.
This inherent non-deterministic nature of the field of Natural Language Processing makes it an interesting and an NP-hard problem. In this sense, understanding NLP is like creating a new form of intelligence in an artificial manner that can understand how humans understand language; which is why NLP is a subfield of Artificial Intelligence. NLP experts say that if humans don’t agree 100% on NLP tasks (like language understanding, or language translation), it isn’t possible to model a machine to perform these tasks without some degree of error. Side note - if an NLP consultant ever tells you that they can create a model that is more precise than a human, be very wary of them. More about that in my post about 7 questions to ask before you hire your Data Science consultant.
Rule-Based NLP vs Statistical NLP
NLP separated into two different sets of ideologies and approaches.
One set of scientists believe that it is impossible to completely do NLP without some inherent background knowledge that we take for granted in our daily lives such as freezing temperatures cause hypothermia, hot coffee will burn my skin and so on. This set of knowledge is collectively known as commonsense knowledge and has brought about the field of Commonsense Reasoning and very many conferences and companies (a special mention to Cyc).
Encoding commonsense knowledge is a very time intensive and manual effort driven process as is considered to be in the space of Rules-Based NLP. It is hard because commonsense knowledge isn’t found in the written text (discourse), and we don’t know how many rules we need to create, before the work for encoding knowledge is complete. Here is an example: as humans, we inherently understand the concepts of death and you will rarely find documents that describe it by explaining the existence and nonexistence of hydrocarbons. Similarly are the concepts of moving and dancing which usually do not require any explanation to a human, but a computer model requires the breakdown of moving into the origin, destination, and the concept of not being at the origin after the move has happened. Dancing, on the other hand, is also a type of moving, but it is obviously very different from a traditional move, and requires more explanation because you can move a lot and still end up in your original location, so what is the point of a dance move?
Another set of scientists have taken a different (now deceptively mainstream) approach to NLP. Instead of creating commonsense data that is missing in textual discourse, their idea is to leverage large amounts of already existing data for NLP tasks. This approach is statistical and inductive in nature and the idea is that if we can find enough number of examples of a given problem, we could potentially solve it using the power of induction. Statistical NLP makes heavy use of Machine Learning for developing models and deriving insights from a labeled text.
Rule-Based NLP and Statistical NLP use different approaches for solving the same problems. Here are a couple of examples:
Parsing:
- Rules-Based uses Linguistic rules and patterns. E.g English has the structure of SVO (Subject Verb Object), Hindi has SOV (Subject Object Verb).
- Statistical NLP induces linguistic rules from the text (so our models are only as good as our text), along with lots of labeling of the text to predict the most likely parse tree of a new data source.
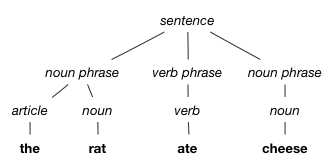 |
| Natural Language Parsing. Image Credit: cs.cornell.edu |
Synonym extraction
- Rules-Based approaches use thesaurus and lists. Data sources such as Wordnet are very useful for deterministic rule-based approaches
- Statistical NLP approaches use statistics to induce thesaurus based on how similar words have similar contexts
| Synonyms using Word2Vec. Image Credit: oscii-lab |
Sentiment Analysis
- Rules-based approaches look for linguistic terms such as “love”, and “hate”, “like” and “dislike” etc. and deterministically classify text as positive and negative
- Statistical NLP approaches use Machine Learning and do some feature engineering to provide weights to linguistic terms to determine the positive and negative nature of texts.
Which approach is better? Both the approaches have their advantages. Rules-based approaches mimic the human mind and present highly precise results, however, they are limited by what we provide as rules. Statistical approaches are less precise, but they have a much higher coverage than rules-based systems as they are able to account for cases that are not explicitly specified in the rules.
Most institutions prefer to use a hybrid approach to NLP, using Rule-Based along with Statistical Systems.
Solving NLP Problems
We use NLP every day when we do a google search. Search engines use Information Retrieval in their backend, which is one of the subfields of NLP.
NLP had earned its popularity because of several mainstream types of language-based problems - such as text summarization, sentiment analysis, keyword extraction, question answering, conversational interfaces and chatbots, machine translation, to name a few.
Conclusion
Today NLP is largely statistical because of the availability of massive amounts of data. We can use tools like Word2Vec to get us similarly occurring concepts, and search engines like Elastic Search to organize our text to make it searchable. We are able to use off the shelf tools like Stanford Core NLP to parse our data for us and other algorithms like Latent Dirichlet Allocation (LDA) to discover clusters and topics in the text.
As a consumer, we use NLP every day - from your first google search of the day, to your curated daily news articles delivered to you, your online shopping experience and reading reviews, and your conversational assistants such as OK Google, Alexa, and Siri.
NLP is embedded in our everyday lives, and we use it even without realizing it. The latest wave of conversational interfaces or chatbots are adding a human component to conversation, and we are finally blending the 2 approaches to NLP - Rule-Based and Statistical NLP.
Where do we go from here? I am excited for the future of NLP, and although we are very far from NLP/AI taking over the world I am optimistic about computational power being more ingrained in our lives to make the world a better and easier place for us.
To learn more about NLP and for additional NLP resources check out this cool blog post from Algorithmia.